Los ácidos nucleicos son macromoléculas formadas por la unión de unidades básicas denominadas nucleótidos. Dicha unión se realiza mediante un tipo de enlace conocido como puente fosfodiéster. Se puede considerar que los nucleótidos son los sillares estructurales de los ácidos nucleicos, del mismo modo que los aminoácidos lo son de las proteínas o los monosacáridos de los polisacáridos. Además de desempeñar el papel de almacenadores y transmisores de la información genética, los nucleótidos como tales tienen otras funciones biológicas de naturaleza energética o coenzimática.
1. Nucleótidos
1.1. Constituyentes químicos de los nucleótidos
Cuando se somete a los ácidos nucleicos a hidrólisis en condiciones suaves liberan sus unidades monoméricas constitutivas: los nucleótidos. Los sillares estructurales de otras macromoléculas, como los aminoácidos o los monosacáridos, no son susceptibles de descomponerse a su vez en unidades más simples; sin embargo los nucleótidos sí pueden sufrir hidrólisis dando lugar a una mezcla de pentosas, ácido fosfórico y bases nitrogenadas. Cada nucleótido está compuesto por una pentosa, una molécula de ácido fosfórico y una base nitrogenada enlazados de un modo característico.
Las pentosas que aparecen formando parte de los nucleótidos son la β-D-ribosa y su derivado, el desoxiazúcar 2'-β-D-desoxirribosa, en el que el grupo hidroxilo unido al carbono 2' fue sustituido por un átomo de hidrógeno.
El tipo de ácido fosfórico que se encuentra en los nucleótidos es concretamente el ácido ortofosfórico.
Las bases nitrogenadas son compuestos heterocíclicos que, gracias al sistema de dobles enlaces conjugados que poseen en sus anillos, poseen un acusado carácter aromático, siendo su conformación espacial planar o casi planar. Sus átomos de nitrógeno poseen pares electrónicos no compartidos que tienen tendencia a captar protones, lo que explica su carácter débilmente básico. Los compuestos originarios de los que derivan estas bases nitrogenadas son la purina y la pirimidina.

Existen formando parte de los nucleótidos dos derivados de la purina (bases púricas), que son la adenina y la guanina, y tres derivados de la pirimidina (bases pirimídicas), que son la citosina, la timina y el uracilo. Todas ellas se obtienen por adición de diferentes grupos funcionales en distintas posiciones de los anillos de la purina o de la pirimidina. Las características químicas de estos grupos funcionales les permiten participar en la formación de puentes de hidrógeno, lo que resulta crucial para la función biológica de los ácidos nucleicos.
Las bases nitrogenadas se pueden formular mediante diferentes estructuras químicas en las que la distribución de los átomos de hidrógeno y los dobles enlaces es distinta. Son formas resonantes que proporcionan estabilidad a las moléculas y se denominan tautómeros.

1.2. Los nucleósidos
Las pentosas se unen a las bases nitrogenadas dando lugar a unos compuestos denominados nucleósidos. La unión se realiza mediante un enlace N-glucosídico entre el átomo de carbono carbonílico de la pentosa (carbono 1') y uno de los átomos de nitrógeno de la base nitrogenada, el de la posición 1 si ésta es pirimídica o el de la posición 9 si ésta es púrica.
Para distinguir qué átomos pertenecen a la pentosa y cuáles a la base nitrogenada se emplean en la primera números con apóstrofe (por ejemplo, diríamos que la adenina se une al C1' de la ribosa).
El enlace N-glucosídico es una variante del tipo más habitual de enlace glucosídico (O-glucosídico), que se forma cuando un hemiacetal intramolecular reacciona con una amina, en lugar de hacerlo con un alcohol, liberándose una molécula de agua.

Los nucleósidos en estado libre sólo se encuentran en cantidades mínimas en las células, generalmente como productos intermediarios en el metabolismo de los nucleótidos. Existen dos tipos de nucleósidos: los ribonucleósidos, que contienen β-D-ribosa como componente glucídico, y los desoxirribonucleósidos, que contienen β-D-desoxirribosa. En la naturaleza se encuentran ribonucleósidos de adenina, guanina, citosina y uracilo, y desoxirribonucleósidos de adenina, guanina, citosina y timina. Los nucleósidos se nombran añadiendo la terminación -osina al nombre de la base nitrogenada si ésta es púrica o bien la terminación -idina si ésta es pirimídica, y anteponiendo el prefijo desoxi- en el caso de los desoxirribonucleósidos.



1.3. Los nucleótidos
Los nucleótidos resultan de la unión mediante enlace éster de la pentosa de un nucleósido con una molécula de ácido fosfórico. Esta unión, en la que se libera una molécula de agua, puede producirse en cualquiera de los grupos hidroxilo libres de la pentosa, pero como regla general tiene lugar en el que ocupa la posición 5'; es decir, los nucleótidos son los 5' fosfatos de los correspondientes nucleósidos. La posesión de un grupo fosfato, que a pH 7 se encuentra ionizado, confiere a los nucleótidos un carácter marcadamente ácido.


Además de los nucleótidos monofosfato que acabamos de describir, que son los sillares estructurales de los ácidos nucleicos, existen en la naturaleza nucleótidos di- y trifosfato, que resultan de la unión mediante enlace anhidro de 1 ó 2 moléculas de ácido fosfórico adicionales a la que se encuentra unida al carbono 5' de la pentosa (Figura 9.4).

Al igual que los nucleósidos, los nucleótidos pueden clasificarse en ribonucleótidos y desoxirribonucleótidos según contengan ribosa o desoxirribosa respectivamente. Existen diversas maneras de nombrar los nucleótidos; cada nucleótido se identifica mediante tres letras mayúsculas, la primera de ellas es la inicial de la base nitrogenada, la segunda indica si el nucleótido es Mono~, Di~, o Trifosfato, y la tercera es la inicial del grupo fosfato; en el caso de los desoxirribonucleótidos se antepone una "d" minúscula a estas tres siglas.

1.4 Funciones de los nucleótidos
Además de ser los sillares estructurales de los ácidos nucleicos (función estructural), los nucleótidos desempeñan en las células otras funciones muy importantes:
B) Moléculas transportadoras de energía; los enlaces fosfoéster que unen los grupos fosfato adicionales de los nucleótidos di~ y trifosfato son enlaces ricos en energía: necesitan un aporte energético importante para formarse y liberan esta energía cuando se hidrolizan. Esto les permite actuar como transportadores de energía.
En concreto, el trifosfato de adenosina (ATP) actúa universalmente en todas las células transportando energía, en forma de energía de enlace de su grupo fosfato terminal, desde los procesos metabólicos que la liberan hasta aquellos que la requieren. En algunas reacciones del metabolismo, otros nucleótidos trifosfato como el GTP, CTP y UTP, pueden sustituir al ATP en este papel.

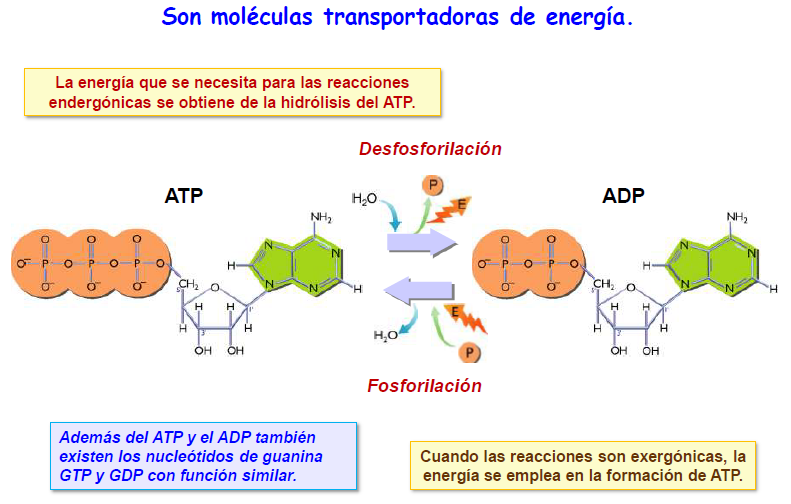
Si existe mucha energía disponible se formarán muchas moléculas de ATP a partir de ADP, por lo que la proporción ATP/ADP será alta. Si la cantidad de energía disponible para la célula es pequeña, disminuirá los niveles de ATP y aumentará los de ADP, por lo que la proporción ATP/ADP será más baja.
La energía desprendida en las reacciones exergónicas se utiliza para formar ATP a partir de ADP y ácido fosfórico (fosforilación), mientras que la energía que se necesita en las reacciones endergónicas procede de la liberada cuando el ATP se hidroliza a ADP y ácido fosfórico (desfosforilación).
Es habitual representar los enlaces de alta energía que existen entre los grupos fosfato con el símbolo virgulilla (~) en lugar de con la notación habitual (-).

Otros ribonucleótidos análogos al ATP, como el GTP, UTP y CTP desempeñan un papel más limitado como transferidores de energía.
C) Moléculas con función coenzimática; algunos nucleótidos o sus derivados pueden actuar como coenzimas (sustancias orgánicas no proteicas que resultan imprescindibles para la acción de muchos enzimas) en algunas reacciones enzimáticas importantes. Tal es el caso del:
· Nicotinamín adenin dinucleótido (NAD+); es un derivado de la vitamina B3 o nicotinamina.

· Nicotinamin adenín dinucleótido fosfato (NADP+); semejante a la anterior pero con un grupo fosfato en el carbono 2' del nucleótido de adenina.

· Flavín adenín dinucleótido (FAD+); es un derivado de la vitamina B2 o rivoflavina.


Las cuatro coenzimas participan en reacciones de deshidrogenación, que son fundamentales en el catabolismo celular. En estas deshidrogenaciones toman H+ y electrones de algunas y quedan como NADH, NADPH, FADH2 y FMNH2 (se les denomina comúnmente poder reductor porque en esa forma pueden reducir a otras moléculas transmitiéndoles esos protones y electrones). Estas acciones desempeñan un papel básico en las reacciones metabólicas de oxidación-reducción.
· Coenzima A: está formado por el ácido pantoténico (vitamina B5) unido a un ADP (adenosín-difosfato). La parte activa de la molécula es un grupo tiol (radical –SH), por eso también se representa como CoA-SH, y actúa como transportador de grupos acetilo (cadenas hidrocarbonadas de dos carbonos) y grupos acilo (cadenas hidrocarbonadas de “n” carbonos).


D) AMPc; este nucleótido interviene en el desencadenamiento de las respuestas de la célula ante las informaciones que recibe del medio extracelular. La unión de moléculas mensajeras como las hormonas y los neurotransmisores a determinados receptores específicos de la membrana plasmática activan la enzima adenil ciclasa que cataliza la siguiente reacción:
ATP → AMPc + P-P
El AMPc sintetizado permite la ejecución de varios procesos bioquímicos que, en última instancia, originan la respuesta celular. Actúa por lo tanto como un mediador entre la información externa y la respuesta final. Por ese motivo se le suele denominar segundo mensajero.


2. Los ácidos nucleicos: enlace o puente fosfodiester
Los ácidos nucleicos son polímeros de nucleótidos. En ellos la unión entre las sucesivas unidades nucleotídicas se realiza mediante enlaces tipo éster-fosfato que resultan de la reacción entre el ácido fosfórico unido al carbono 5' de la pentosa de un nucleótido y el hidroxilo del carbono 3' de la pentosa de otro nucleótido. Este tipo de unión, en la que un grupo fosfato queda unido por dos enlaces éster a dos nucleótidos sucesivos, se conoce también como puente fosfodiéster.
Cuando dos nucleótidos se unen mediante un puente fosfodiéster el dinucleótido que resulta conserva un grupo 5' fosfato libre en un extremo que puede reaccionar con el grupo hidroxilo 3' de otro nucleótido, y un grupo hidroxilo 3' libre que puede reaccionar con el grupo 5' fosfato de otro nucleótido. Esta circunstancia permite que mediante enlaces fosfodiéster se puedan enlazar un número elevado de nucleótidos para formar largas cadenas lineales que siempre tendrán en un extremo un grupo 5' fosfato libre y en el otro un grupo hidroxilo 3' libre.





Del mismo modo que se definió la estructura primaria de las proteínas como su secuencia de aminoácidos, se puede definir la estructura primaria de los ácidos nucleicos como su secuencia de nucleótidos. Los ácidos nucleicos poseen un esqueleto de las mismas características, formado por una sucesión alterna de pentosas y grupos fosfato, a partir del cual se proyectan lateralmente las distintas bases nitrogenadas.


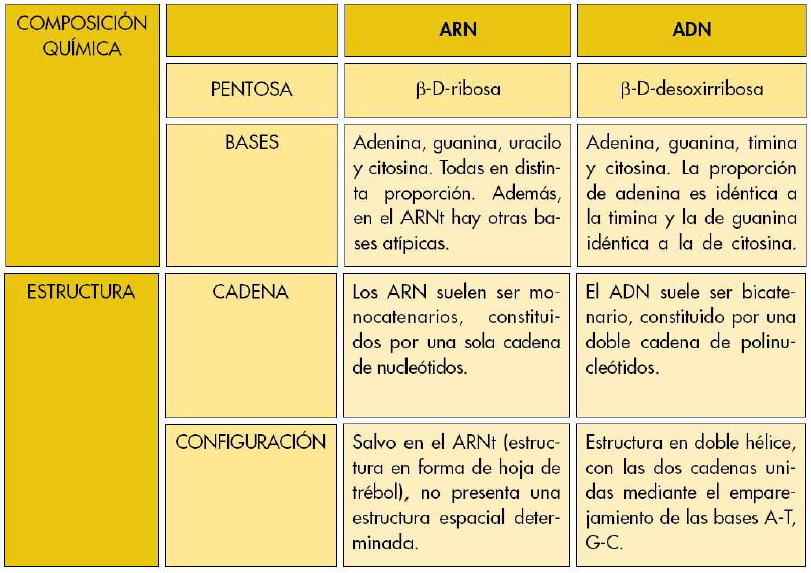
3. El ácido desoxirribonucleico o ADN
El ADN es un ácido nucleico constituido por la polimerización de desoxirribonucleótidos. Es una molécula formada por dos cadenas polinucleótidas antiparalelas enrolladas en una doble hélice. Las dos cadenas permanecen unidas gracias a los enlaces de puentes de hidrógeno que se establecen entre las bases nitrogenadas de ambas.


Normalmente se encuentra en el núcleo de la célula (ADN nuclear), en el cromosoma bacteriano, en el interior de las mitocondrias (ADN mitocondrial) o de los cloroplastos (ADN plastidial).
Las principales funciones del ADN son:
a) El ADN contiene la información genética codificada en la secuencia de sus bases nitrogenadas. Según sean su orden y su distribución, así serán las proteínas que se sinteticen siguiendo las instrucciones del código genético, que hacen corresponder la secuencia de bases nitrogenadas del ADN con la secuencia de aminoácidos de la proteína.
b) La segunda propiedad del ADN es que puede duplicarse (replicación)lo que asegura la conservación de la información genética y su transmisión a la descendencia.
3.1. Estructura 1ª del ADN
La estructura primaria del ADN es la secuencia de nucleótidos (unidos por enlaces fosfodiéster) de una sola cadena o hebra, que puede presentarse como un simple filamento extendido o bien algo doblada en sí misma.
Como hemos visto, una cadena de ADN presenta dos extremos libres: el 5´, unido al grupo fosfato, y el 3´, unido a un hidroxilo.

A comienzos de los años 50, tres centros de investigación rivalizaban en el análisis de la estructura tridimensional de las biomoléculas mediante cristalografía de rayos X. Uno de ellos era el Instituto de Tecnología de California, cuya división de química, dirigida por Linus Pauling, se había apuntado varios éxitos notables en el descubrimiento de la estructura secundaria de las proteínas.
Otro era el Laboratorio Cavendish de la Universidad de Cambridge (Inglaterra). Fue en el Laboratorio Cavendish donde coincidieron a comienzos de 1951 dos jóvenes investigadores, James D. Watson y Francis H.C. Crick, que estaban llamados a ser quienes desvelaran finalmente la estructura de la molécula de ADN.
Un tercer grupo se había formado en el King’s College de Londres bajo la jefatura de John Randall, que contaba con la colaboración de Maurice Wilkins y de la experta cristalógrafa Rosalind Franklin.
Entre 1951 y 1953 se desató entre estos grupos una especie de carrera por identificar la estructura tridimensional del ADN, carrera que se aceleró cuando la publicación del experimento de Hershey y Chase a finales de 1952 puso a todos los grupos sobre la pista correcta de cual era en realidad la molécula de la herencia.
En el King’s College, Rosalind Franklin había desarrollado una técnica que le permitía obtener fibras de ADN altamente orientadas y obtener así difractogramas de rayos X de una calidad y lujo de detalles muy superiores a los conocidos hasta entonces.


Mientras tanto Watson y Crick trataban de construir su propio modelo tridimensional basándose en difractogramas de una calidad muy inferior. No obstante, su trabajo se encontraba muy avanzado; habían analizado cuidadosamente la estructura de los nucleótidos individuales y se habían percatado de que los datos obtenidos por Chargaff tres años antes, sobre las proporciones de las bases nitrogenadas (comprobó que todos los ADN tenían el mismo número de A que de T y de C que de G), debían tener algún significado relevante, lo que probablemente fue una de las claves de su éxito posterior.
Fue entonces cuando Jim Watson, durante una conversación con Maurice Wilkins, pudo ver algunos de los difractogramas obtenidos por Rosalind Franklin; la simple inspección visual de aquellos difractogramas proporcionó a Watson las claves que le faltaban para resolver finalmente la estructura del ADN.
En pocas semanas Watson y Crick terminaron de encajar sus propios datos con lo que se apreciaba en los difractogramas de Franklin y elaboraron un modelo definitivo que fue publicado en el número de abril de la revista Nature. La carrera había terminado.

El modelo propuesto por Watson y Crick, mundialmente conocido como la doble hélice, presentaba las siguientes características:
a) La molécula de ADN está formada por dos cadenas polinucleotídicas antiparalelas, es decir, si una cadena se recorre en dirección 5’—›3’, su vecina discurriría en dirección 3’—›5’.

b) Ambas cadenas se encuentran formando un arrollamiento helicoidal de tipo plectonémico, es decir, para separarlas habría que desenrollarlas girando una sobre la otra. El arrollamiento es además dextrógiro.

c) El conjunto forma una estructura cilíndrica con un diámetro constante de 2 nm.
d) Los esqueletos azúcar-fosfato de las cadenas polinucleotídicas se encuentran en el exterior de la estructura, formando lo que serían las guías de una especie de escalera de caracol.
e) Las bases nitrogenadas se proyectan desde los esqueletos azúcar-fosfato hacia el interior de la estructura y se disponen apiladas por pares formando lo que equivaldría a los peldaños de la escalera.
f) Los pares de bases nitrogenadas están formados invariablemente por una purina y una pirimidina (complementarias). Además, siempre se encuentran enfrentadas adenina con timina por una parte y guanina con citosina por otra.
g) Las dos cadenas polinucleotídicas se encuentran unidas por puentes de hidrógeno entre grupos funcionales de las bases nitrogenadas que forman cada par. Cada adenina forma dos puentes de hidrógeno con la correspondiente timina y cada guanina tres con la citosina. Pares de bases diferentes a los establecidos no podrían formar puentes de hidrógeno.

h) La distancia entre cada par de bases sucesivo es de 0,34 nm. Cada vuelta completa de la hélice (paso de rosca) alberga exactamente 10 pares de nucleótidos, lo que se corresponde con una longitud de 3,4 nm. Ambas periodicidades aparecían reflejadas en los difractogramas.



Uno de los aspectos más interesantes del modelo de Watson y Crick residía en que no sólo encajaba con los datos de difracción de rayos X sino que además proporcionaba una explicación para la hasta entonces desconcertante regla de Chargaff. En efecto, si todos los pares de bases eran necesariamente A-T o G-C, en cualquier muestra de DNA el número de restos de adenina debía ser igual al de timina y el de guanina al de citosina, de lo que se deduce que el número total de bases púricas debería ser igual al de bases pirimídicas.
Además, este emparejamiento específico de las bases nitrogenadas podría encerrar un profundo significado biológico, pues, como Watson y Crick sugerían en su artículo en Nature, tal emparejamiento podría ser la base del mecanismo por el que el material genético creaba copias de si mismo en cada ciclo de reproducción celular. La complementariedad interna de la doble hélice, regida por la regla de Chargaff, hacía que cada una de las dos cadenas polinucleotídicas que la formaban pudiera ser utilizada como molde para sintetizar otra con una secuencia de bases complementaria.
La publicación del modelo de Watson y Crick en abril de 1953 y la gran difusión que tuvo en los meses posteriores diluyó rápidamente cualquier resto de escepticismo acerca del papel del ADN como material hereditario, que ya no volvió a ser discutido. Todo ello supuso una auténtica revolución en el seno de las ciencias biológicas y el nacimiento de lo que se dio en llamar biología molecular, área del conocimiento que tuvo un gran desarrollo en las décadas siguientes y que ha contribuido de forma decisiva a nuestra comprensión actual del funcionamiento de los sistemas vivos.

3.2.1 Estructuras alternativas a la doble hélice de Watson y Crick (forma B)
Aunque la doble hélice descrita por Watson y Crick, la llamada forma B (forma que adopta el ADN en disolución y en la que interacciona con las proteínas nucleares), ha sido considerada como la única conformación espacial posible, actualmente se conocen otras formas posibles:
A) Forma A del ADN; es una doble hélice dextrógira, como la forma B, pero los pares de bases no forman un plano perpendicular al eje, sino inclinados 20º con respecto al eje de la hélice. Es más ancha y corta que la forma B.
La forma A sólo se ha observado en laboratorio, formada a partir de la forma B cuando la humedad relativa desciende al 75%.
B) Forma Z del ADN; la forma Z del ADN es más larga y estrecha que la forma B. Es levógira, gira en sentido antihorario. Su forma la debe a la presencia de numerosos nucleótidos de guanina y citosina alternantes (GCGCGCGC).
C) Forma bicatenaria circular; en procariotas, mitocondrias y cloroplastos el ADN es una molécula bicatenaria y circular.
D) ADN de cadena simple; en algunos virus las cadenas de ADN son sencillas, no dobles, y pueden ser circulares o lineales.

3.3. Estructura 3ª del ADN
La estructura terciaria es la disposición que adopta la fibra de ADN de doble hélice al asociarse con las proteínas para formar los cromosomas. La estructura terciaria varía según se trate de organismos procariotas o eucariotas:
a) En procariotas el ADN se pliega como una superhélice, generalmente en forma circular y asociada a una pequeña cantidad de proteínas. Lo mismo ocurre en orgánulos celulares como las mitocondrias y en los cloroplastos.
b) En eucariotas, dado que la cantidad de ADN de cada cromosoma es muy grande, el empaquetamiento ha de ser más complejo y compacto; para ello se necesita la presencia de proteínas, como las histonas y otras proteínas de naturaleza no histónica (en los espermatozoides estas proteínas son las protaminas).
3.3.1 Estructura 3ª del ADN en procariotas
Aunque se pensaba que la estructura terciaria del ADN era exclusiva del núcleo de la célula eucariota y de los cromosomas, también el ADN de bacterias, mitocondrias y cloroplastos tiene cierta estructura terciaria, estando asociado a otras proteínas parecidas a las histonas formando el nucleoide.
La estructura terciaria de las moléculas de ADN circular de las bacterias o de las mitocondrias, consiste en que la fibra de 20 Å se enrolla sobre sí misma (por acción de las enzimas ADN-topoisomerasas II) formando una especie de superhélice, por lo que se denomina ADN superenrollado.



El ADN superenrollado presenta dos ventajas:
a) La estructura es más estable porque la longitud del ADN es menor.
b) Facilita el proceso de duplicación del ADN, ya que el enrollamiento del ADN superenrollado es hacia la derecha, al contrario que el provocado por las enzimas que desespiralizan el ADN para iniciar su duplicación, abriendo la molécula.
3.3.2 Estructura 3ª del ADN en eucariotas
La estructura terciaria del ADN de la célula eucariota puede ser de dos tipos:
a) Fibra nucleosómica o collar de perlas: el ADN está asociado a histonas, constituyendo la cromatina que, en la división celular, se condensará para formar los cromosomas.
b) Estructura cristalina: el ADN está asociado a protaminas, proteínas más básicas que las histonas. Se da en espermatozoides, donde se necesita que el núcleo tenga un ADN más compacto.
3.3.2.1 Fibra nucleosómica o collar de perlas
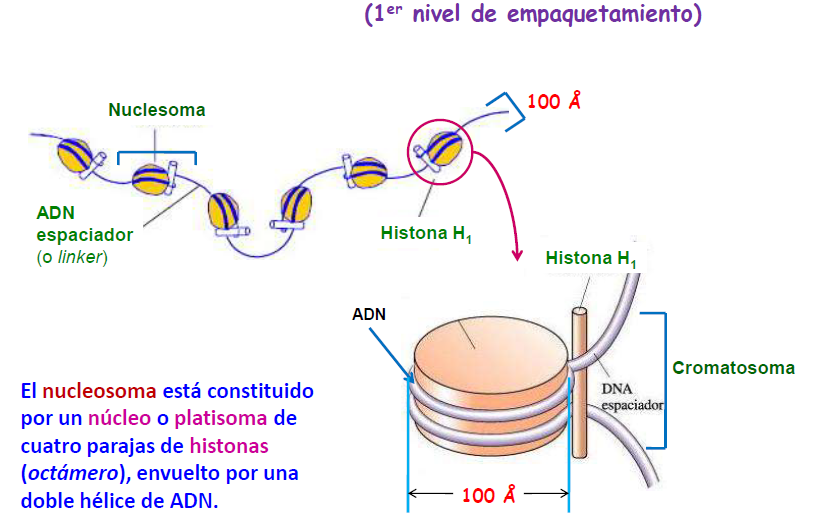
La fibra nucleosómica, o collar de perlas, o fibra de cromatina de 100 Å o estructura arrosariada, aparece en las células eucariotas somáticas en interfase (no están en división) formando la cromatina.
La fibra nucleosómica está formada por una sucesión de nucleosomas, partículas de unos 100 Å de diámetro. El nucleosoma es una estructura que constituye la unidad fundamental de la cromatina, que es la forma de organización del ADN en las células eucariotas. Se trata de ADN de doble hélice de unos 200 pares de bases nitrogenadas. Los nucleosomas están formados por:
A) El núcleo o core que está constituido por:
· Un octámero de histonas (proteínas ricas en aminoácidos básicos), formado por dos moléculas de cada una de las histonas H2a, H2b, H3 y H4.
· Unos 146 pares de bases nitrogenadas de ADN que se disponen a alrededor del octámero dando 1,75 vueltas.
B) El ADN espaciador o linker es el ADN que hay entre dos núcleos consecutivos. Consta de 54 pares de bases, unos 27 pares de bases nitrogenadas a cada lado.
Entre dos nucleosomas consecutivos hay un lazo internucleosómico de entre 15 y 100 bases de ADN. Entre dos nucleosomas, la histona H1 se asocia a 10 pares de nucleótidos de cada nucleosoma, dando dos vueltas completas.
Cuando se condensa la fibra nucleosómica durante la mitosis y meiosis, se hacen visibles los cromosomas.




3.3.2.2 La estructura cristalina
En los espermatozoides, el núcleo sólo tiene la mitad del ADN que las células somáticas (no reproductoras), y está formado por ADN y protaminas.
Las protaminas son proteínas más básicas y pequeñas que las histonas. La mayor atracción entre el ADN y las protaminas provoca que estén mucho más empaquetados que la fibra nucleosómica, constituyendo la estructura cristalina.
3.4. Estructura 4ª del ADN
Cuando la fibra nucleosómica de 100 Å o de cromatina se enrolla helicoidalmente (fibra de 300 Å), con seis nucleosomas en cada vuelta, acortando en cinco veces la longitud de la fibra nucleosómica de 100 Å lo denominamos solenoides. Las histonas H1 quedan en el interior de la hélice formando el eje de la misma.


Hay un tercer nivel de empaquetamiento en el cuál se forman rosetones de bucles (700 Å) al enrollarse los solenoides alrededor de un armazón de proteínas no histónicas enrolladas en espiral y, finalmente un nuevo enrollamiento alrededor del eje del cromosoma que forma una espiral de rosetones (7 000 Å).


3.5. Desnaturalización y renaturalización del ADN
La doble hélice del ADN es muy estable en condiciones normales debido a los numerosos puentes de hidrógeno que unen entre sí a las dos cadenas. Ahora bien, si se calienta, o se somete a cambios de pH o a cambios en las condiciones iónicas del medio, los puentes de hidrógeno se rompen y las dos cadenas se separan, este proceso es la desnaturalización.
Se llama temperatura de fusión a aquella Tª en la que el 50% de la doble hélice está separada. Su valor depende de la composición de bases del ADN. Las moléculas de ADN ricas en pares C-G tienen una Tª de fusión más elevada que las que tienen más pares de puentes de hidrógeno A T (porque tienen un mayor número de puentes de hidrógeno).
El proceso de desnaturalización es reversible, es decir, si se recuperan las condiciones iniciales las dos cadenas se vuelven a unir restableciéndose la doble hélice, a este proceso se le llama renaturalización. La renaturalización permite que se produzca la hibridación, es decir que se puedan unir dos hebras de distinta procedencia y formar una molécula híbrida, siempre que entre ambas hebras exista una secuencia complementaria. Cuanto más relacionados están los ADN mayor porcentaje de renaturalización se producirá. La hibridación se utiliza con distintas finalidades, por ejemplo, estudios de parentesco evolutivo entre diferentes especies, detectar enfermedades genéticas o investigación criminal.


4. El ácido ribonucleico o ARN
Se comprobó que en las células eucariotas la casi totalidad del ADN celular se encuentra en el interior del núcleo mientras que la mayor parte del ARN se encuentra en el citoplasma (aunque algunas zonas del núcleo, en particular el nucléolo, también son ricas en ARN). Por otra parte, del total de ARN citoplasmático una fracción muy importante se encontraba asociado a determinadas proteínas para formar unas partículas, visibles al microscopio electrónico, que fueron denominadas ribosomas. Experimentos realizados utilizando aminoácidos marcados radiactivamente pronto demostraron que los ribosomas eran el lugar de la célula donde se llevaba a cabo la síntesis de las proteínas, por lo que ya desde entonces se asoció al ARN con este proceso.
La estructura tridimensional del ARN difiere claramente de la del ADN. En general las moléculas de ARNson monocatenarias (una sola cadena polinucleotídica). Sin embargo, existen moléculas de ARN que, aun siendo monocatenarias, presentan tramos con secuencias de bases complementarias los cuales adoptan estructuras en doble hélice, denominadas horquillas, de características análogas a las del ADN. En ocasiones, cuando las secuencias complementarias no son contiguas, se forman bucles de bases no emparejadas dentro de las horquillas. En las dobles hélices de ARN la adenina se empareja con el uracilo, que tiene estructura similar e idénticas posibilidades de formar puentes de hidrógeno que la timina, y la guanina con la citosina.

Hoy sabemos que la función primordial del ARN en las células consiste en servir de intermediario para transferir la información genética cifrada en el ADN a la estructura tridimensional de las proteínas en el proceso de expresión de la información genética.
De todos modos, en algunos virus el ARN constituye en sí mismo el material genético además de servir de intermediario en el proceso de síntesis de las proteínas virales. En algunos de estos virus la molécula de ARN que constituye el cromosoma viral es bicatenaria y presenta en toda su longitud estructura de doble hélice. También existen virus con cromosomas de ARN monocatenario.
4.1 Tipos de ARN
Existen varios tipos de ARN que difieren en el tamaño, estructura y función específica de sus moléculas. Todos ellos se sintetizan en el núcleo celular a partir de secuencias de ADN que sirven como molde y una vez sintetizados atraviesan los poros nucleares y se incorporan a sus diferentes destinos en el citoplasma:
4.1.1 ARN ribosómico (ARNr)
El ácido ribonucleico ribosómico o ribosomal (ARNr) es el tipo de ARN más abundante (80-85% del ARN total) en las células y constituye, en un 60% del peso, los ribosomas. Estos se encargan de la síntesis de proteínas según la secuencia de nucleótidos presente en el ARN mensajero.
El ARNr presenta segmentos lineales y segmentos en doble hélice (estructura secundaria), debido a la presencia de secuencias complementarias de ribonucleótidos a lo largo de la molécula.
El peso de los ARNr y de los ribosomas se suele expresar según el coeficiente de sedimentación (S) de Svedberg, que es directamente proporcional a la velocidad de sedimentación de la partícula durante la ultracentrifugación. El coeficiente de sedimentación se expresa en unidades svedberg (S), siendo un svedberg equivalente a 10-13 segundos.
Las células procariotas presentan ribosomas de 70 S, menor peso que los de las células eucariotas, de 80 S.


Sus moléculas son relativamente pequeñas (75 a 90 nucleótidos de longitud). Presentan una estructura característica con horquillas y bucles que les dan el aspecto de hojas de trébol cuando se representan sobre un plano: su estructura tridimensional presenta en realidad forma de L invertida. El ARNt presenta bases nitrogenadas diferentes a las características de los ácidos nucleicos en una proporción que puede alcanzar el 10% del total. Su función consiste en transportar de manera específica a los diferentes aminoácidos hasta los ribosomas para que allí sean ensamblados en las cadenas polipeptídicas en formación. Existen alrededor de 50 tipos de ARNts que difieren en sus secuencias de nucleótidos y en algunos aspectos de su conformación tridimensional; sin embargo todos ellos comparten algunas características:
· en el extremo 5’ de la cadena polinucleotídica hay un triplete de bases nitrogenadas una de las cuales es siempre guanina.
· en el extremo 3’ la cadena polinucleotídica finaliza con la secuencia CCA y estas bases no están emparejadas. En este lugar es donde el ARNt se une a su aminoácido correspondiente.
· la molécula presenta tres brazos cada uno de los cuales consta de una horquilla con estructura en doble hélice y un bucle formado por bases sin emparejar (Figura 19.16). Se distinguen el brazo T (por donde la molécula se une al ribosoma), el brazo D (lugar que reconocen los enzimas específicos que unen los ARNt con sus aminoácidos correspondientes) y el brazo A (cuyo bucle presenta un triplete de bases, denominado anticodón, que es complementario de otro triplete, llamado codón, que se encuentra en el ARN mensajero, siendo esta complementariedad de gran importancia en el proceso de síntesis de proteínas).




El ARNm es monocatenario, básicamente lineal y sólo constituye el 2-5 % del ARN total.
La función del ARNm es tomar la información del ADN, que está en núcleo, y llevarla al citoplasma, donde están los ribosomas en los que se sintetizarán las proteínas con los aminoácidos aportados por los ARNt.
El ARNm se forma a partir de una hebra del ADN en un proceso llamado transcripción. Se crea, con las bases nitrogenadas complementarias, un molde con la información genética necesaria para la síntesis de proteínas. El tamaño del ARNm depende del tamaño de la proteína para la que lleva información.

En el citoplasma, las enzimas ribonucleasas, lo van a ir destruyendo para evitar la producción innecesaria de proteínas. Cuando se vuelva a necesitar la síntesis de una proteína concreta, se creará nuevo ARNm.
La información que contiene el ARNm se presenta en una secuencia de bases nitrogenadas, agrupadas en tripletes o codones, cada uno de los cuales determina la unión de un determinado aminoácido.

El ARNm tiene distinta estructura en procariotas y en eucariotas:
A) ARNm en eucariotas; el ARN mensajero obtenido después de la transcripción se conoce como ARN transcrito primario o ARN precursor o pre-ARN, que en la mayoría de los casos no se libera del complejo de transcripción en forma totalmente activa, sino que ha de sufrir modificaciones antes de ejercer su función (procesamiento o maduración del ARN). Entre esas modificaciones se encuentran la eliminación de fragmentos (splicing), la adición de otros no codificados en el ADN y la modificación covalente de ciertas bases nitrogenadas.
El ARN transcrito primario (pre-ARNm), está formado por dos tipos de segmentos que se alternan:
· Exones, segmentos con información.
· Intrones, segmentos sin información que serán suprimidos y no aparecen en el ARNm.

El ARNm eucariótico posee en su extremo 5' una caperuza (CAP), formada por un nucleótido derivado de la guanina, que da estabilidad al ARNm y permite el acceso al ribosoma para la síntesis de proteínas. Después hay un segmento sin información, seguido de otro segmento con información que empieza con las bases AUG.
En el extremo 3' aparecen unos 200 nucleótidos de adenina, la llamada “cola” de poli-A, que protege la molécula frente a las enzimas exonucleasas.

El ARNm eucariótico es monocistrónico, es decir, sólo contiene información para sintetizar una cadena polipeptídica.
B) ARNm en procariotas; el proceso de transcripción y el de traducción se realizan de manera similar que en las células eucariotas. La diferencia fundamental está en que, en las procariotas, el ARN mensajero no pasa por un proceso de maduración y, por lo tanto, no se le añade caperuza ni cola ni se le quitan intrones. Además, no tiene que salir del núcleo como en las eucariotas, porque en las células procariotas no hay un núcleo definido.
El ARNm en procariotas es policistrónico, contiene informaciones separadas para sintetizar distintas proteínas.


4.1.4 ARN nucleolar (ARNn)
El ARNn forma parte del nucléolo. Se origina a partir de la región del ADN denominada región organizadora nucleolar (NOR). Este ARN monocatenario de 45 S se asocia a proteínas procedentes el citoplasma para formar las subunidades de los ribosomas.
4.1.5 Otros tipos de ARN
El ARN pequeño nuclear (ARNpn) es llamado así por su pequeño tamaño y por encontrarse en el núcleo de las células eucariotas. También se le denomina ARN-U, por su elevado contenido en uracilo. Como los demás ARN, el ARNpn es monocatenario.
El ARNpn se une a ciertas proteínas del núcleo formando las ribonucleoproteínas nucleares, para realizar el proceso de eliminación de intrones (maduración del ARNm).
El ARN antisentido es la hebra complementaria y no codificadora de un hebra ARNm.
Si en una célula se transcribiese, además de la hebra codificante de ADN que sirve como molde, una cadena de ARN que resultara complementaria o antisentido del ARNm correspondiente, éstos podrían interceptar al ARNm transcripto al formarse un ARN de doble cadena. El apareamiento de las dos hebras de ARN da lugar a una molécula de doble cadena que no puede traducirse y es degradada enzimáticamente.
En los laboratorios de biología molecular y biotecnología, se utiliza esta propiedad del ARN para bloquear la expresión de un gen de interés.
Los ARN interferentes (ARNi) son moléculas de ARN que suprimen la expresión de genes específicos mediante diversos mecanismos. Los ARN interferentes son moléculas pequeñas de 20 a 25 nucleótidos que se generan por fragmentación de precursores más largos, entre ellos destacan los microARN (miARN) y los ARN interferentes pequeños (ARNip). En células animales reprimen la expresión génica al menos de cuatro formas diferentes:
a) degradación de la proteína durante la traducción.
b) inhibición de la elongación de la traducción.
c) terminación prematura de la traducción (disgregación de los ribosomas) o inhibición de la iniciación de la traducción.
Por otro lado, se están utilizando los nuevos conocimientos en el mecanismo de silenciamiento génico post transcripcional para silenciar genes. Este fenómeno puede ser utilizado como herramienta para identificar genes “blanco” para el desarrollo de nuevas drogas, eliminar la función de un gen en particular y hasta eliminar, potencialmente, la expresión de genes responsables de ciertas enfermedades. El sistema CRISPR/Cas9 que se verá más adelante también se vale de una guía de ARN, para encontrar el gen ADN de interés.
Los ribozimas son ARN con función catalítica (son las únicas enzimas no proteícas). Unos llevan a cabo reacciones de automodificación, como eliminación de intrones o autocorte, mientras que los otros actúan sobre substratos distintos. Actualmente sabemos que el ARN ribosómico de mayor tamaño (28S en eucariotas y 23S en procariotas) tiene actividad de ribozima al catalizar la formación del enlace peptídico durante la síntesis de proteínas.
El descubrimiento de la función catalítica de las ribozimas ha llevado a una revolución en el área de la biología molecular. Las ribozimas podrían ser sintetizadas y modificadas, y serán una potente herramienta biotecnológica para degradar ARN específicos. Por ejemplo se podría utilizar para proteger organismos contra virus, bacterias u hongos patógenos eliminando específicamente sus ARN.
5. Funciones de los ácidos nucleicos
Podemos destacar dos funciones principales que desempeñan los ácidos nucleicos en las células:
A) Almacenamiento de la información genética; en el caso de las células, tanto eucariotas como procariotas, y en el de algunos virus, esta función la cumple el ADN. En el resto de los virus es el ARN el encargado de ella. En cualquier caso, el almacenamiento de información genética va implícito en la secuencia de bases nitrogenadas que presente el ácido nucleico correspondiente.
B) Transmisión de la información genética; es el ARN, en sus diversos tipos, el encargado de realizar esta misión, lo que lleva a cabo mediante la síntesis de proteínas. El ARNm se copia de un trozo de ADN y saca la información fuera del ADN (núcleo). Dicha información es "leída" e "interpretada" por los ribosomas, que contienen ARN-r. En función de la información "leída", los distintos tipos de ARN-t transportan a los aminoácidos para la síntesis proteica.

No hay comentarios:
Publicar un comentario